#1575 Issue closed: Rescue fails ERROR: Starting RPC portmapper rpcbind failed¶
Labels: bug, support / question, fixed / solved / done
 tjgruber opened issue at 2017-11-14 20:09:¶
tjgruber opened issue at 2017-11-14 20:09:¶
Relax-and-Recover (ReaR) Issue Template¶
-
rear version (/usr/sbin/rear -V):

-
OS version (cat /etc/rear/os.conf or lsb_release -a):

-
rear configuration files (cat /etc/rear/site.conf or cat /etc/rear/local.conf):

-
Are you using legacy BIOS or UEFI boot?
legacy BIOS -
Brief description of the issue:
Everything works fine until I boot to the recovery ISO or (any) recovery media. Once I'm in, and type "rear recover", it fails. I am also unable to start the mentioned daemons. Below is a screenshot of what happens

Here's the log file at /ver/log/rear/rear-serv-build.log:
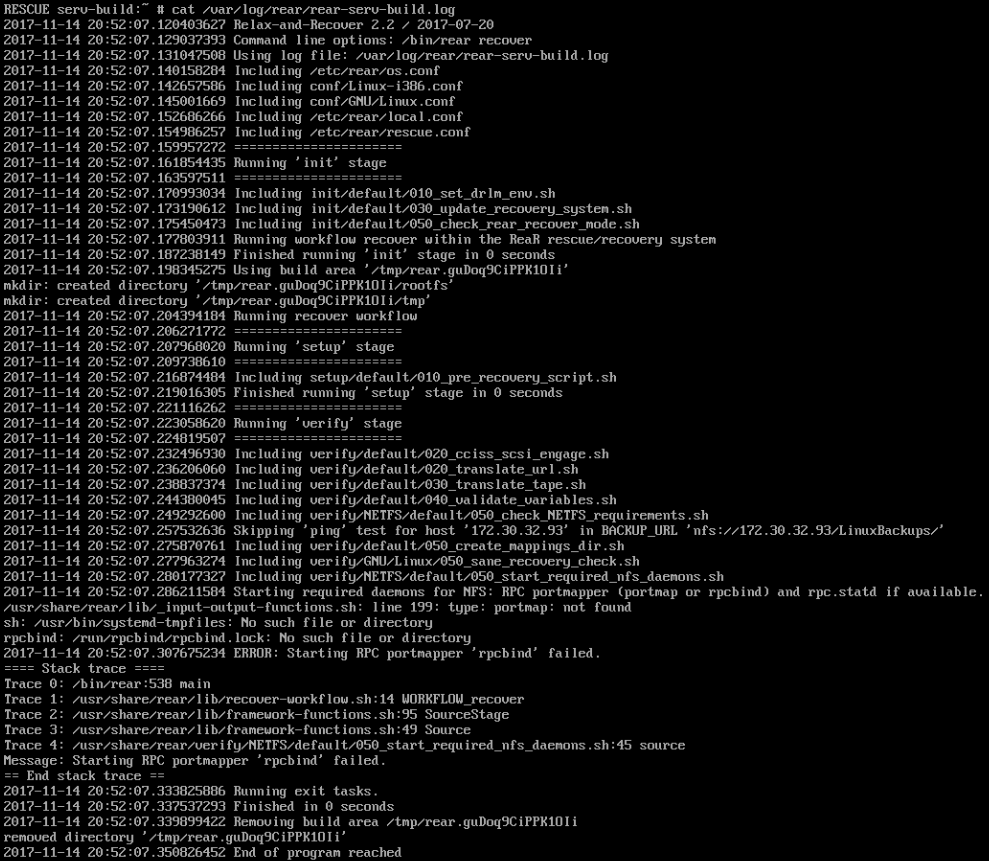
- Work-around, if any: N/A
 jsmeix commented at 2017-11-15 14:31:¶
jsmeix commented at 2017-11-15 14:31:¶
I am not a Fedora user so that I cannot reproduce
what goes on on your particular system.
Regarding how you could debug what the root cause is
on your particular system you may have a look at the section
"Debugging issues with Relax-and-Recover" in
https://en.opensuse.org/SDB:Disaster_Recovery
In your particular case the script that shows the
"Starting RPC portmapper ... failed" error message is
usr/share/rear/verify/NETFS/default/050_start_required_nfs_daemons.sh
therein this code
rpcinfo -p &>/dev/null || rpcbind || Error "Starting RPC portmapper '$portmapper_program' failed."
i.e. calling 'rpcbind' in the ReaR recovery system
failed in your particular case with
rpcbind: /run/rpcbind/rpcbind.lock: No such file or directory
which indicates that the directory /run/rpcbind/
is missing in the ReaR recovery system.
As a workaround for now you may create that directory
in the running ReaR recovery system before
you call "rear recover".
If that helps, you can add the command that creates
the missing directory to the PRE_RECOVERY_SCRIPT
config variable, see usr/share/rear/conf/default.conf
to automate your workaround.
If that makes things work, we can create the missing directory
in an appropriate ReaR script.
tjgruber commented at 2017-11-15 16:27:¶
Once logged in to the recovery console, I created the /run/rpcbind
direcotry.
That fixed the issue.
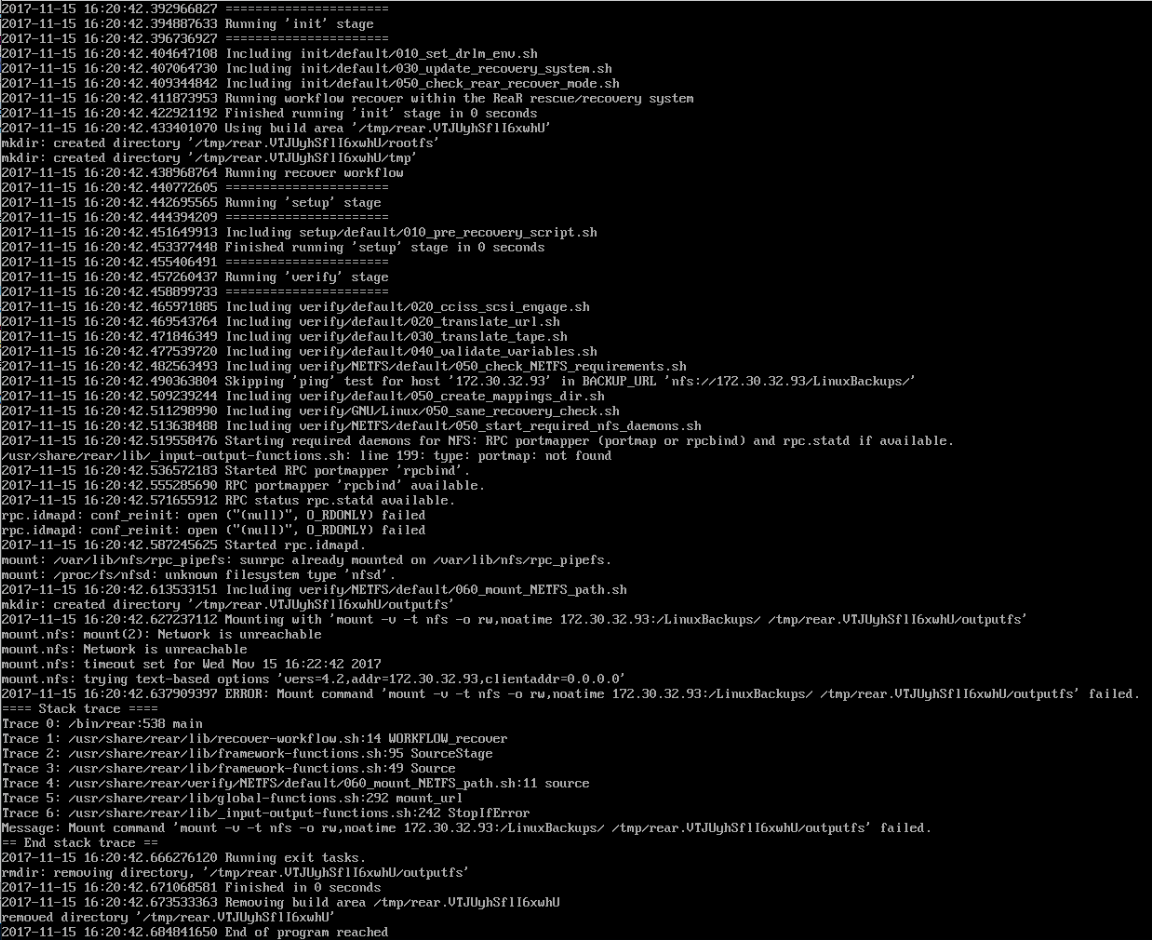
However, there is now another issue of no network connectivity for some reason. An "ifconfig" shows no IP address.
 gozora commented at 2017-11-15 16:38:¶
gozora commented at 2017-11-15 16:38:¶
@tjgruber if you are really struggling with ReaR setup and can't find solution by your own, I can try to install Fedora and take a look what can be wrong there, just let me know.
V.
tjgruber commented at 2017-11-15 16:41:¶
I'm still working on it.
I found this:
https://github.com/rear/rear/issues/1177
which may help me. I'm in the process of trying out a few things. If I'm
unable to get it working after this I'll let you know.
Thank you!
gozora commented at 2017-11-15 16:45:¶
@tjgruber for that network issue of yours.
Automatic network setup can be quite a pain in the ..., but you can
easily bring you network up as follows:
Either:
ifconfig <dev_name> inet <IP_address> netmask <mask>
or
ip a add <ipaddress>/<mask_suffix> dev <dev_name>
ip link set <dev_name> up
V.
tjgruber commented at 2017-11-15 17:10:¶
Running the following allowed the recovery process to begin:
mkdir /run/rpcbind
chmod a+x /etc/scripts/system-setup.d/60-network-devices.sh
/etc/scripts/system-setup.d/60-network-devices.sh
However, now things are stuck again.
I just don't think ReaR was meant to run on Fedora.
Edit: here's the log file instead of lots of screenshots:
jsmeix commented at 2017-11-15 17:14:¶
FYI regarding commands as in
https://github.com/rear/rear/issues/1575#issuecomment-344653352
I take (again) the opportunity to advertise my glorious
NETWORKING_PREPARATION_COMMANDS
cf. usr/share/rear/conf/default.conf ;-)
gozora commented at 2017-11-15 17:21:¶
@tjgruber don't be upset, as far as I remember you are the first one opening issue for Fedora ;-), so yes there might be some trouble indeed, but I guess is is nothing we can't overcome ...
It looks like you've maybe hit some bug in code of mine (XFS filesystem
recreation).
Would you mind uploading your rescue ISO somewhere, where I can get my
dirty hands on it?
That ISO contains configuration files that might help me to find out
where the problem is and possibly patch it.
Thanks in advance
V.
tjgruber commented at 2017-11-15 17:23:¶
I edited my post:
https://github.com/rear/rear/issues/1575#issuecomment-344661234
with the actual log file and got rid of the screenshots.
tjgruber commented at 2017-11-15 17:26:¶
don't be upset, as far as I remember you are the first one opening issue for Fedora ;-), so yes there might be some trouble indeed, but I guess is is nothing we can't overcome ...It looks like you've maybe hit some bug in code of mine (XFS filesystem recreation).Would you mind uploading your rescue ISO somewhere, where I can get my dirty hands on it?That ISO contains configuration files that might help me to find out where the problem is and possibly patch it.Thanks in advanceV.
I'll see what I can do.
The .ISO is 200MB. Is there anything specific I can get from it instead?
gozora commented at 2017-11-15 17:32:¶
@tjgruber quickest way for me to find the problem is to boot your ISO
...
So you can upload it to dropbox maybe?
If you have whatever problem with it for whatever reason I will accept
it, and install my own Fedora instance and test it there ...
V.
tjgruber commented at 2017-11-15 17:38:¶
My only problem is that I don't know what is in there, and if there would be anything company specific or any passwords or anything like that.
I'm checking it out.
tjgruber commented at 2017-11-15 17:45:¶
@gozora if you do want to install Fedora 26, I used LVM and XFS on all relevant partitions.
Here's a screenshot of the partitions I have:

gozora commented at 2017-11-15 18:22:¶
My only problem is that I don't know what is in there, and if there would be anything company specific or any passwords or anything like that.
Understood! Better be safe than sorry :-)
Could you provide me at least with content of following directory /var/lib/rear/layout ?
Thx
V.
tjgruber commented at 2017-11-15 18:32:¶
@gozora
Could you provide me at least with content of following directory /var/lib/rear/layout ?
Is that from the .ISO or from the server?
gozora commented at 2017-11-15 18:32:¶
Original server
tjgruber commented at 2017-11-15 19:38:¶
No, that last "rear recover" killed the partitions.
gozora commented at 2017-11-15 19:48:¶
let's try something.
Once you boot ReaR rescue ISO go to /var/lib/rear/layout/xfs , edit
every file with suffix .xfs
where you remove string sunit=0 blks from log section so it looks
something like this:
[root@fedora xfs]# diff -uNp fedora-root.xfs.nosunit fedora-root.xfs
--- fedora-root.xfs.nosunit 2017-11-15 20:47:37.591982649 +0100
+++ fedora-root.xfs 2017-11-15 20:45:29.427460249 +0100
@@ -6,5 +6,5 @@ data = bsize=4
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal bsize=4096 blocks=2560, version=2
+ = sectsz=512 lazy-count=1
- = sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
and run rear recover again.
V.
gozora commented at 2017-11-15 19:59:¶
Hello @sandeen,
Hope you are fine these days.
Once you've left a
https://github.com/rear/rear/issues/1065#issuecomment-309479672
here, remember? ;-)
I just hope you don't mind answering simple question:
I'm looking on two different XFS versions 4.5.0 and 4.10.0
When I run following command on 4.5.0 all is OK:
mkfs.xfs -f -i size=512 -d agcount=4 -s size=512 -i attr=2 -i projid32bit=1 -m crc=1 -m finobt=1 -b size=4096 -i maxpct=25 -d sunit=0 -d swidth=0 -l version=2 -l sunit=0 -l lazy-count=1 -n size=4096 -n version=2 -r extsize=4096 /dev/loop0
however same command on XFS 4.10.0 returns
Illegal value 0 for -l sunit option. value is too small
I'm not sure if this is bug or feature :-(, why is 0 suddenly considered illegal ?
Thanks
V.
tjgruber commented at 2017-11-15 20:12:¶
@gozora I'm not sure what you mean where you say:
remove string sunit=0 blks from log section
Here's the contents of /var/lib/rear/layout/xfs:

Here is the default contents of the "fedora_serv--build-root.xfs"
file:
(I'm not sure what to change)

gozora commented at 2017-11-15 20:19:¶
Open fedora_serv--build-root.xfs with vi, remove sunit=0 blks,
and save file.
repeat with sda1.xfs and sdb2.xfs
Your log section should look something like this:
log =internal bsize=4096 blocks=9600, version=2
= sectsz=512 lazy-count=1
After this change rear recover should run just fine.
V.
tjgruber commented at 2017-11-15 20:35:¶
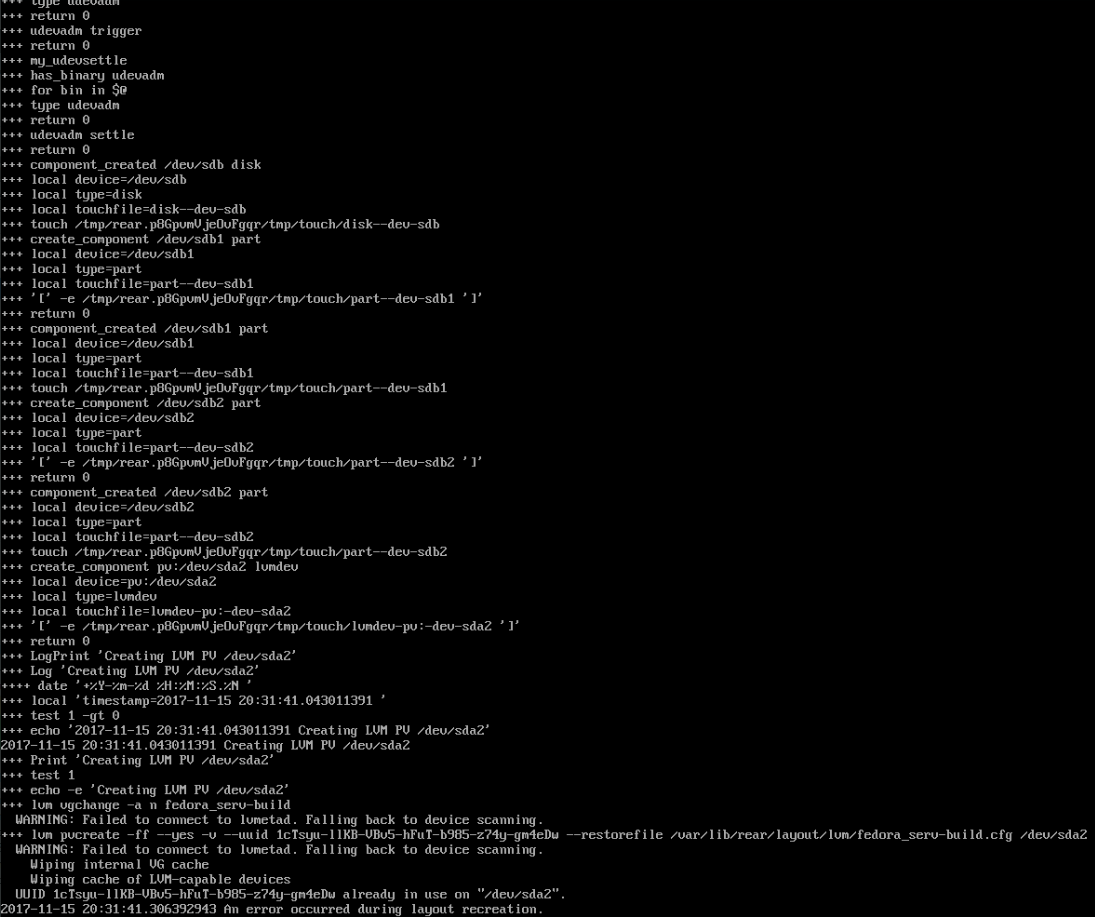
It failed again with an error, here's the end of the log:
tjgruber commented at 2017-11-15 20:39:¶
And here are the file contents:

gozora commented at 2017-11-15 20:40:¶
This error have nothing to do with XFS from before.
You have probably some remaining LVM structure present from your
previous rear recover session.
You need to umount and remove all existing LVM structures (lvremove,
vgremove) and partitions (fdisk) before running rear recover again.
V.
gozora commented at 2017-11-15 20:43:¶
@tjgruber I'm on https://gitter.im/rear/rear, so just drop me a message if you need help ...
tjgruber commented at 2017-11-15 21:06:¶
Okay I think I figured it out.
I ran the following two commands to get a list of logical volumes and volume groups:
lvdisplay
vgdisplay
Then I used the following commands to remove them appropriately.
lvremove
vgremove
It looks like things are in process, so I'll let you know in a few minutes what happens.
tjgruber commented at 2017-11-15 21:22:¶
It looks like a successful recovery to me. Thank you to everyone for the great support! It's very much appreciated and will help everyone else using Fedora, LVM and XFS.
SELinux had to do some relabeling, which it did automatically, and after that, I was able to successfully boot back into the recovered Fedora 26 server.

To summarize what worked:
# Create missing directory:
mkdir /run/rpcbind
# Manually start networking:
chmod a+x /etc/scripts/system-setup.d/60-network-devices.sh
/etc/scripts/system-setup.d/60-network-devices.sh
# Navigate to and list files in /var/lib/rear/layout/xfs
# Edit each file ending in .xfs with vi and remove "sunit=0 blks" from the "log" section.
# In my case, the following files, then save them:
vi /var/lib/rear/layout/xfs/fedora_serv--build-root.xfs
vi /var/lib/rear/layout/xfs/sda1.xfs
vi /var/lib/rear/layout/xfs/sdb2.xfs
# Run the following commands to get a list of LVs and VGs:
lvdisplay
vgdisplay
# Run the following commands to remove the above listed LVs and VGs:
lvremove
vgremove
# Now run recovery again:
rear recover
gozora commented at 2017-11-15 21:34:¶
Poking around xfsprogs sources this new behavior was introduced in
version 4.7.0 ... :-/.
I'm not sure how we should approach this.
My expectation during writing of XFS recreate code was that every option
from xfs_info output can be passed as option to mkfs.xfs which
proved to be wrong! :-(
In my opinion best and most harmless way would be to simply ignore every
option=0 pair from xfs_into as omitting such pair seems to be valid
way for mkfs.xfs.
I'll wait couple of days whether we will get some inputs on this from
@sandeen, and write patch afterwards.
@schlomo, @gdha, @jsmeix, @schabrolles as always, any inputs are more than welcome!
V.
gozora commented at 2017-11-15 21:36:¶
I'll open separate issue for xfs problem tomorrow (or Friday), so we don't mix topics here ...
gozora commented at 2017-11-15 21:37:¶
It looks like a successful recovery to me.
Glad you've made it!
Thank you to everyone for the great support! It's very much appreciated and will help everyone else using Fedora, LVM and XFS.
Anytime
jsmeix commented at 2017-11-16 11:01:¶
@gozora
I assume you will work on the XFS related parts but
I do not know what you have planned for me to work on ;-)
I.e. on what parts of this issue should I work
(so that we avoid duplicate work on same parts)?
jsmeix commented at 2017-11-16 11:14:¶
@gozora
regarding your proposal/question in
https://github.com/rear/rear/issues/1575#issuecomment-344735974
"ignore every option=0":
First and foremost I am not a XFS user
so that I know basically nothing about XFS and
I know even less than nothing ;-) about XFS internals.
In general I think "ignore every option=0" is dangerous because
for some options the value 0 could be right and explicitly intended
compared to not specify this option and use the mkfs.xfs default.
In particular boolean options usually have '0' as valid value,
e.g. from "man mkfs.xfs" on my SLES12 system
where /usr/sbin/mkfs.xfs is from xfsprogs-4.3.0
crc=value
This is used to create a filesystem which
maintains and checks CRC information in
all metadata objects on disk.
The value is either 0 to disable the feature,
or 1 to enable the use of CRCs.
gozora commented at 2017-11-16 11:31:¶
Hello @jsmeix
I assume you will work on the XFS related parts but
I do not know what you have planned for me to work on ;-)
I.e. on what parts of this issue should I work
(so that we avoid duplicate work on same parts)?
I basically assigned you here because you've been commenting on this
issue ;-).
This issue can be closed and I'll open new one for this particular XFS
problem.
In general I think "ignore every option=0" is dangerous because
for some options the value 0 could be right and explicitly intended
compared to not specify this option and use the mkfs.xfs default.
Good point!
Then I'd need to ignore just non-boolean values, I guess ... This would
create a bit hard to maintain code, but unfortunately I don't see easier
way around.
V.
jsmeix commented at 2017-11-16 12:41:¶
@gozora
"man mkfs.xfs" on my SLES12 system with xfsprogs-4.3.0
shows this non-boolean option where 0 is a valid value:
maxpct=value
This specifies the maximum percentage
of space in the filesystem that can be
allocated to inodes. The default value
is 25% for filesystems under 1TB, 5%
for filesystems under 50TB and 1% for
filesystems over 50TB.
...
Setting the value to 0 means that essentially
all of the filesystem can become inode blocks,
subject to inode32 restrictions.
which is an example for settings where
the value 0 has a special meaning like
"timeout=0" could mean unlimited waiting or
"max_space=0" could mean unlimited space
and things like that.
gozora commented at 2017-11-16 12:59:¶
@jsmeix thanks for info.
It looks like we can't really write a some general rule ;-/, "love
it!"
Will try to think about it a bit more ...
V.
gozora commented at 2017-11-16 15:56:¶
I'm closing this issue as solved, and opening #1579 as follow up for XFS issue that occurred here.
 gdha commented at 2017-11-29 15:46:¶
gdha commented at 2017-11-29 15:46:¶
Update for Fedora 26 - the skel/default/run/rpcbind directory will be
masked by the new mounted /run mount-point. Therefore, the problem
as described in this issue is not yet fixed.
gdha commented at 2017-11-29 16:59:¶
The solution is to copy the systemd-tmpfiles executable and copy as is
the directory /var/lib/tmpfiles.d as this will generate the
/run/rpcbind directory during the start-up of rpcbind daemon. Will
make a PR for this.
gdha commented at 2017-12-12 15:12:¶
The fix proofs to be working as I could do a successful recovery with
NFS (rpcbind started automatically).
OK to close this issue.
[Export of Github issue for rear/rear.]